Paper:https://arxiv.org/abs/2010.04159
Code:https://github.com/fundamentalvision/Deformable-DETR
介绍
最近提出的 DETR 消除了目标检测中很多手工设计的组件,然而降低了精度。除此之外,由于受到 Tranformer attention 模块在处理图片特征的限制,导致它收敛很慢,并且限制了特征空间分辨率。
为了解决上述问题,论文提出了 Deformable DETR,它的 attention 模块仅仅关注 参考点 附近的一组关键采样点。Deformable DETR 可以获得比 DETR 更好的性能(尤其是在小物体上),并且训练次数减少了 10 倍。

DETR存在的两个问题:(1)比起现存的目标检测器,它的收敛要求太长时间的训练周期。例如,在COCO数据集上,DETR 需要 500 epochs 才能收敛,而这大约比 Faster RCNN 慢了 10~20 倍。(2)DETR 在检测小目标上存在较低的性能。当前的检测器通常利用多尺度特征,这这些特征上小目标可以从高分辨率特征上被检测。然而,高分辨率的特征图给 DETR 带来的严重的计算代价。 上述问题主要归因于 Transformer 组件在处理图像特征图方面的不足。在初始化的时候,attention modules 将几乎统一的注意力权重投射到特征图中的所有像素。让学习注意力权重专注于稀疏有意义的位置,长时间的训练周期是必要的。 另一方面,Transformer 编码器中的注意力权重计算是像素数的平方计算量。 因此,处理高分辨率特征图具有非常高的计算和内存复杂性。
在图片领域,deformable 卷积是一种强有力且高效的关注稀疏空间位置的机制。它可以天然的避免上述提到的问题。然而它缺乏元素关系建模机制,这是DETR成功的关键。
在这篇论文中,作者提出 Deformable DETR,它缓解了 DETR 收敛慢和高计算复杂性的问题。它组合了 deformable 卷积的稀疏空间采样特性和 Transformer 的相关性的建模能力。论文提出的 deformable attention 模块将一小组采样位置作为所有特征图像素中重要的关键元素的预过滤器。
由于其快速收敛以及计算和内存效率,Deformable DETR 为我们开辟了利用端到端对象检测器变体的可能性。 作者探索了一种简单有效的迭代边界框细化(iterative bounding box refinement)机制来提高检测性能。 论文还尝试了一个 two-stage Deformable DETR,其中 region proposal 也是由 Deformable DETR 的变体生成的,它们被进一步输入 decoder 以进行 iterative bounding box refinement。
回顾 Transformer 和 DETR
Multi-Head Attention in Transformers
Transformers 是针对机器翻译任务设计的一种基于注意力机制的网络结构。给一个 query 元素(例如,在一个输出句子中的一个目标单词)和一组 key 元素(例如,在输入句子中的原单词),multi-head attention 模块根据注意力权重自适应地汇聚关键信息,这个注意力权重可以测量 query-key 对 质检的一致性。为了允许让模型从不同表示子空间和不同位置中关注信息,不同 attention heads 的输出是使用学到的权重线性聚合的结果。Multi-head attention 特征可以计算为:
\[ \operatorname{MultiHeadAttn}\left(\boldsymbol{z}_{q}, \boldsymbol{x}\right)=\sum_{m=1}^{M} \boldsymbol{W}_{m}\left[\sum_{k \in \Omega_{k}} A_{m q k} \cdot \boldsymbol{W}_{m}^{\prime} \boldsymbol{x}_{k}\right] \]
\(q \in \Omega_{q}\) 表示 一个 query 元素的索引,其特征表示为 \(z_q \in \mathbb{R}^{C}\)
\(k \in \Omega_{k}\) 表示一个 key 元素的索引,其特征表示为 \(x_k \in \mathbb{R}^C\)
\(C\) 特征的维度
\(M\) attention head 的数量,\(m\) 是 attention head 的索引
\(\mathbf{W}_{m}^{\prime} \in \mathbb{R}^{C_{v}\times C}\) 和 \(\mathbf{W}_{m} \in \mathbb{R}^{C_{v}\times C}\) 是可学习的权重,并且 \(C_{v} = C/M\)
\(A_{m q k} \propto \exp \left\{\frac{\mathbf{z}_{q}^{T} \mathbf{U}_{m}^{T} \mathbf{V}_{m} \mathbf{x}_{k}}{\sqrt{C_{v}}}\right\}\) 是 attention 权重,它被归一化,并且 \(\sum_{k\in \Omega_{k}} A_{mqk}=1\) 其中 \(\mathbf{U}_{m}\) 和 \(\mathbf{V}_{m}\) 也是可学习的权重。
为了消除不同空间位置的歧义,表示特征 \(x_q\) 和 \(x_k\) 通常是和 positional embedding 的串联/求和。
DETR
对于 DETR 中的 Transformer encoder,query 和 key 元素都是特征图中的像素。输入是 ResNet 特征图(带有编码的 positional embeddings)。让 \(H\) 和 \(W\) 分别表示特征图的高度和宽度。 self-attention 的计算复杂度为 \(O(H^2 W^2 C)\) ,随空间大小呈二次方增长。
对于 DETR 中的 Transformer dncoder,输入包括来自 encoder 的特征图和 由可学习位置嵌入(例如,N = 100)表示的 N object queries。decoder 中有两种注意力模块,即 cross-attention 和 self-attention 模块。在 cross-attention 模块中,object query 从特征图中提取特征。query 元素属于object queries,key 元素属于encoder 的输出特征图。其中,\(N_q = N\),\(N_k = H \times W\),交叉注意力的复杂度为 \(O(HWC^2 + NHWC)\)。复杂性随着特征图的空间大小线性增长。在 self-attention 模块中,object queries 相互交互,以捕获它们的关系。 query 和 key 元素都是 object queries。 其中,\(N_q = N_k = N\),self-attention 模块的复杂度为 \(O(2NC^2 +N^2 C)\)。 中等数量的对象查询的复杂性是可以接受的。
这主要是因为处理图像特征的注意力模块很难训练。 例如,在初始化时,cross-attention 模块几乎对整个特征图具有平均注意力。而在训练结束时,attention maps 被学习到非常稀疏,只关注对象的外轮廓(extremities)。 似乎 DETR 需要很长的训练才能学习注意力图的如此显着的变化。
Method
Ddformable Transformer for End-To-End Object Detection

Deformable Attention Module
\[ \operatorname{DeformAttn}\left(\boldsymbol{z}_{q}, \boldsymbol{p}_{q}, \boldsymbol{x}\right)=\sum_{m=1}^{M} \boldsymbol{W}_{m}\left[\sum_{k=1}^{K} A_{m q k} \cdot \boldsymbol{W}_{m}^{\prime} \boldsymbol{x}\left(\boldsymbol{p}_{q}+\Delta \boldsymbol{p}_{m q k}\right)\right] \]
这里 \(m\) attention head 的索引,\(k\) 采样 keys 的索引,\(K\) 是总采样的 key 的数量 \((K \ll HW)\)。\(\Delta p_{mqk}\) 和 \(A_{mqk}\) 是采样的偏置和在 \(m^{th}\) attention head 上的 \(k^{th}\) 采样点的 attention weight。
Multi-scale Deformable Attention Module
\[ \operatorname{MSDeformAttn}\left(\boldsymbol{z}_{q}, \hat{\boldsymbol{p}}_{q},\left\{\boldsymbol{x}^{l}\right\}_{l=1}^{L}\right)=\sum_{m=1}^{M} \boldsymbol{W}_{m}\left[\sum_{l=1}^{L} \sum_{k=1}^{K} A_{m l q k} \cdot \boldsymbol{W}_{m}^{\prime} \boldsymbol{x}^{l}\left(\phi_{l}\left(\hat{\boldsymbol{p}}_{q}\right)+\Delta \boldsymbol{p}_{m l q k}\right)\right] \]
Deformable Transformer Encoder
由于提出的 multi-scale deformable attention 可以再不同多尺度特征层上交换信息,所以没有使用 FPN 结构。
在 encoder 中 multi-scale deformable attention 模块的应用中,输出是与输入具有相同分辨率的多尺度特征图。key 和 query 元素都是来自多尺度特征图的像素。对于每一个 query 像素,这个参考点(reference point)就是它自己。为了识别每个 query 像素位于哪个特征级别,除了 positional embedding 之外,我们还向特征表示中添加了 a scale-level embedding,表示为 \(e_l\)。与固定编码的 positional embedding 不同,scale-level embedding \(\{e_l\}^L_l=1\) 是随机初始化并与网络联合训练。
Deformable Transformer Decoder
decoder 中有 cross-attention 和 self-attention 模块。这两种注意力模块的 query 元素都是 object queries。在 cross-attention 模块中,object queries 从特征图中提取特征,其中 key 元素是来自 encoder 的输出特征图。在 self-attention 模块中,object queries 相互交互,其中 key 元素是 object queries。由于我们提出的 deformable attantion 模块是为处理卷积特征图作为 key 元素而设计的,因此我们仅将每个 cross-attention 模块替换为 multi-scale deformable attention 模块,而保持 self-attention 模块不变。对于每个 object query,参考点 \(\hat p_q\) 的二维归一化坐标是从其 object query embedding 中通过可学习的线性投影和 \(\mathrm{sigmoid}\) 函数预测的。
因为 multi-scale deformable attention 模块提取参考点(reference point)周围的图像特征,我们让检测头将边界框预测为相对偏移,也就是参考点进一步降低优化难度。 参考点用作框中心的初始猜测。检测头预测相对偏移,也就是参考点。这样,学习到的 decoder attention 将与预测的边界框有很强的相关性,这也加速了训练收敛。
通过在 DETR 中用 deformable attention 模块替换 Transformer attention 模块,我们建立了一个高效且快速收敛的检测系统,称为 Deformable DETR。
其他改进 和 变体
Iterative Bounding Box Refinemen
Two-Stage Deformable DETR
实验结果

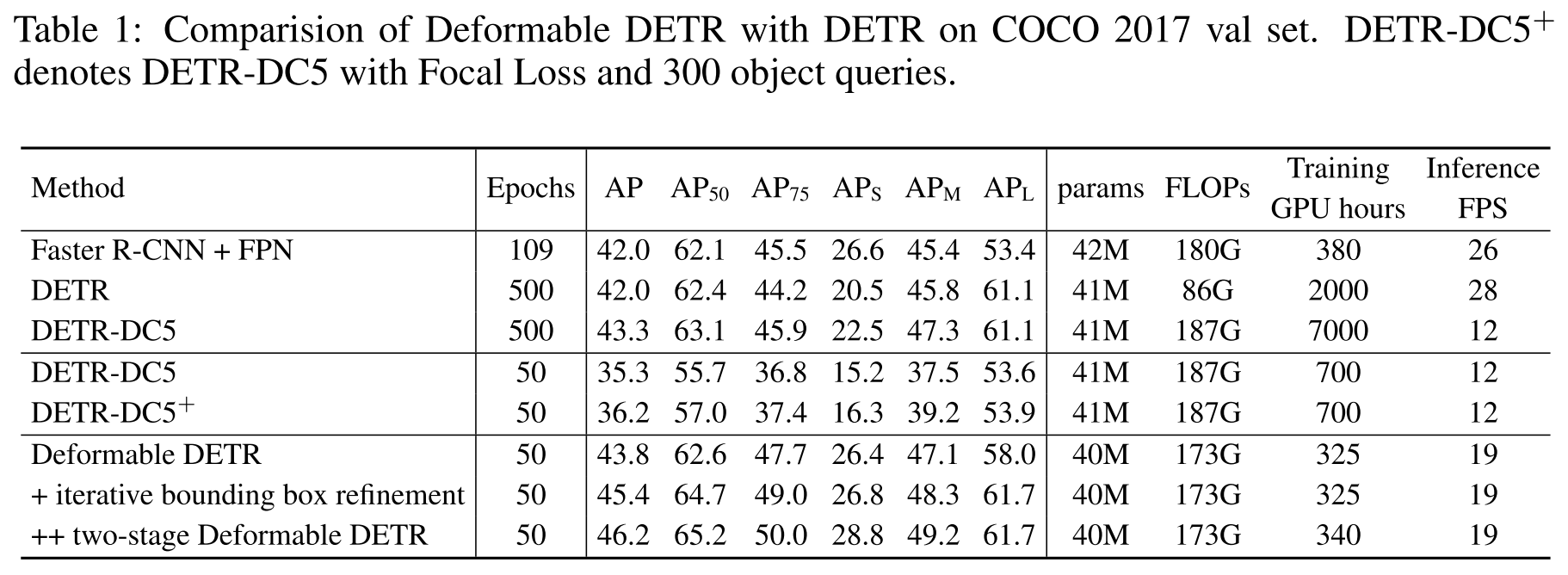
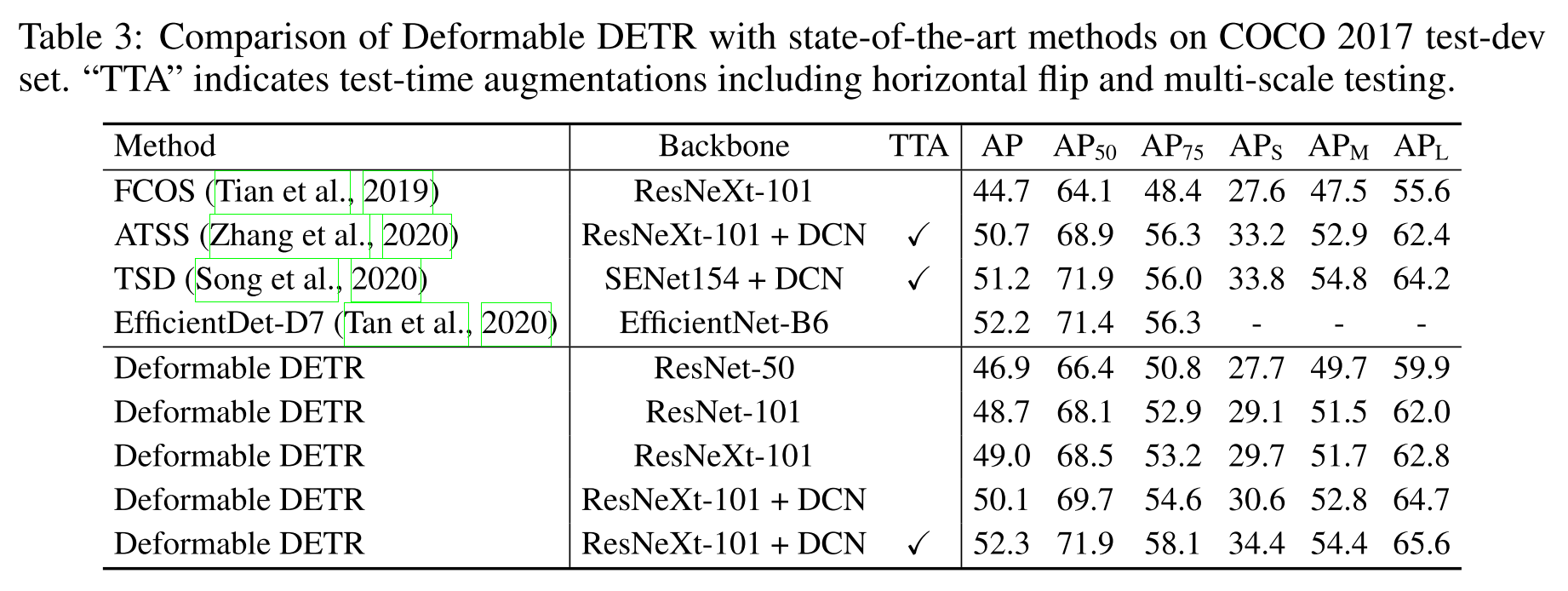
由上图可以看出,Deformable DETR 明显提升了训练速度。
论文中的符号说明


